
TLDR: I rebuilt the blog in go, to vastly simplify it and its dependencies. You are reading this blog on the new implementation
After preaching the case for simplicity over complexity I have taken a harder look at the way I actually built this website.
I ended up with certain keypoints that I wanted to address, since I ended up buying quite heavily into those and it was costing me quite some time for something that on the surface seems rather trivial: “Take these markdown files and parse them to HTML on request to serve them to the user”.
- I have no need for the overhead of what react accomplishes, the site is pretty static
- On top of react I chose to buy into remix, which is another level of opinions that I must learn and reason about
- The fact that I ended up wanting to use Notion as my knowledge base for this, further increased complexity, and I ended up not really using it.
Given these keypoints I decided to spend some time reflecting and figure out how I can simplify the application while also getting a better understanding and more control of the underlying systems that facilitate this setup.
What Changed
In the old implementation I needed to build an API layer that was able to retrieve the blog posts from Notion lazily, and then cache this on success, in order to reduce the overhead of building the HTML on flight. Creating a long lived service inside Remix was not as easy to do as expected, which more or less probably indicats that you should not be doing it like that.
It would have been possible to make the revised implementation inside Remix, where it would just be file based, but to me JavaScript did not feel like the correct tool for that job. I am used to building backends in more robust languages than JS.
This brought me to my distant love:
go. I’ve been using it on and off for some pet projects, and right here it felt like the perfect tool for the job. Parse some *.md files, read the frontmatter metadata embedded in the top of the file and return a properly structured object that can then be transformed into HTML. As a matter of fact I was able to rebuild the entire blog plus extra features in one afternoon, which to me signifies the value in picking the right tradeoffs.The new feature is, that I now can host my drawio diagrams and properly reference them in the blog posts. Furthermore, I am happy to say, that with the use of
gow -e go,html,md,css run . i basically have hot reload nailed down pretty nicely. The last 5% of optimization would be to update the browser when that change is detected, but for now it’s “good enough”.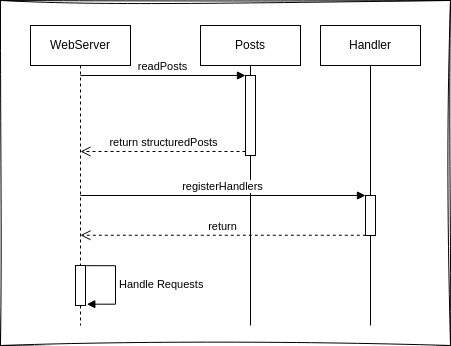
The above diagram indicates the simplicity of the new approach. Start the server, read all files that are publishable into memory and then serve them. That’s it. If at some point I need to release a new blog post, I simply just release a new version. For now this simplicity is worth the tradeoff for me. Of course you could go ahead an make a volume mount that is attached to the webserver, and then just restart it and it would have the latest changes, but that “complexity” is not something I am interested in right now. Furthermore, I actually get version history of my blogs now, which is a neat side effect.
An insight into the simplicity
I want to show a simple example which really brings home to me the simplicity that can occur when nothing is magically implied.
func main() {
posts := lib.GetAllPosts("posts")
r := gin.Default()
r.LoadHTMLGlob("templates/*")
r.Static("/public", "./public")
r.StaticFile("/favicon.ico", "./public/favicon.ico")
r.StaticFile("/images/rubberduck.png", "./public/images/rubber-duck.png")
r.StaticFile("/images/simple-blog-diagram.png", "./public/images/simple-blog-diagram.drawio.png")
r.StaticFile("/robots.txt", "./public/robots.txt")
r.StaticFile("/css/style.css", "./public/css/style.css")
r.GET("/", api.GetIndex(posts))
r.GET("/blog/:slug", api.GetBlogPost(posts))
r.Run()
}
This snippet shows everything that as off the current state is required in order to access every resource that is available through this webserver. Some of these calls such as
r.StaticFile could be made more simple by going through an array or just mapping everything in the public folder to be available, but this choice makes it so that my opinion can easily be adapted based on what I prefer within a heartbeat. This also showcases how easy it is to get a service up and running and be made available to the world.Going forward
So now I’ve managed to address these issues, but what should happen if I actually want a more SPA like behavior or god forbid even some usage of local storage where a user might save some preferences. Stay tuned for another post where I’ll address the matter of getting some reactivity back into an application without relying on react or a home rolled version that attempts something similar. I’ll be using HTMX in order to address this. It will combine the strengths of a backend that can serve HTML (and of course so much more) with the reactivity of a SPA application.
Let’s see where all of this is going. Hopefully this change can serve as inspiration.